
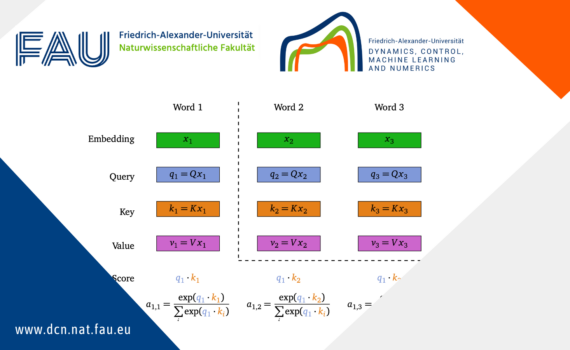
Clustering in discrete-time self-attention Since the article Attention Is All You Need [1] published in 2017, many Deep Learning models adopt the architecture of Transformers, especially for Natural Language Processing and sequence modeling. These Transformers are essentially composed of layers, alternating between self-attention layers and feed forward layers, with normalization […]
Daily Archives: January 30, 2025
1 post