
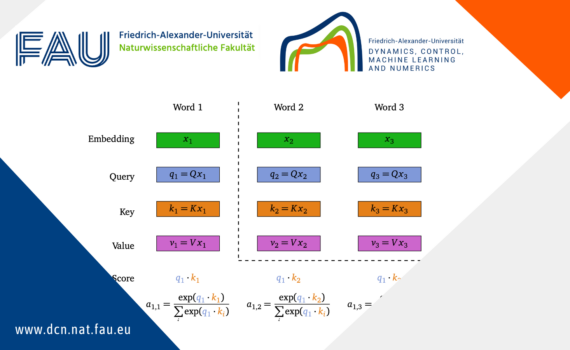
Clustering in discrete-time self-attention Since the article Attention Is All You Need [1] published in 2017, many Deep Learning models adopt the architecture of Transformers, especially for Natural Language Processing and sequence modeling. These Transformers are essentially composed of layers, alternating between self-attention layers and feed forward layers, with normalization […]
Math Lucas Versini
2 posts
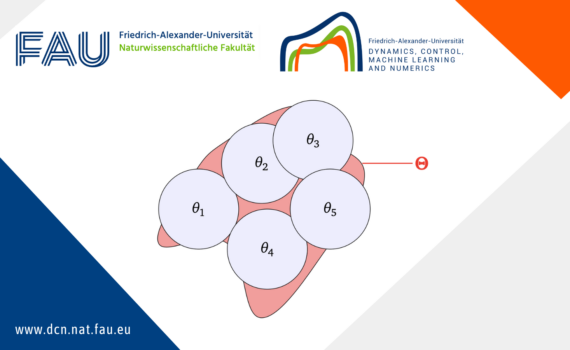
Generalization bounds for neural ODEs: A user-friendly guide Once a neural network is trained, how can one measure its performance on new, unseen data? This concept is known as generalization. While many theoretical models exist, practical models often lack comprehensive generalization results. This post introduces a probabilistic approach to quantify […]