
Federated Learning for Systems Identification
 Noémie Turmel
Noémie TurmelFederated learning (FL) operates in a decentralized manner, as shown Figure 1, allowing multiple clients (or devices) to collaboratively train a model while ensuring the privacy of local data. This method is particularly relevant for systems identification, where clients have access to limited and environmentspecific datasets. The FedSysID algorithm (Wang u. a., 2022) proposes a federated methodology for estimating a global dynamic model by integrating local observations from each client.
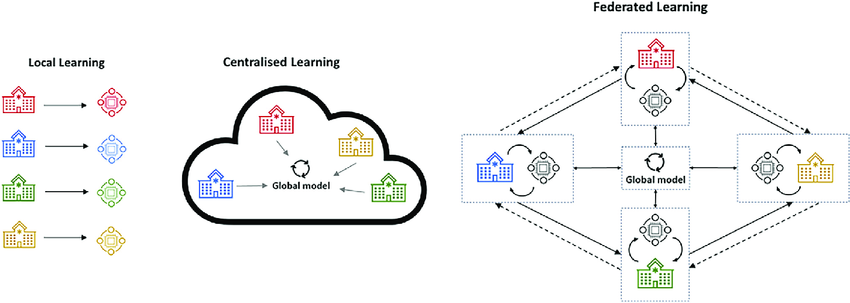
Figure 1. Federated learning in comparison to local learning and centralized learning
1 Context and Problem Statement
In many industrial and scientific scenarios, it is crucial to identify dynamic systems from observed trajectories. However, these observations are often partial, noisy, and distributed across multiple entities. Federated learning enables the pooling of knowledge while preserving the privacy of local data.
In a standard identification setting, the goal is to estimate the evolution matrices of a linear dynamic system:
x_{t+1} = A x_t + B u_t + w_t, \quad \text{ for } t \in \left| [1, T] \right|, (1)
where x_t represents the system state, u_t the input, and w_t the process noise. Each client i observes system trajectories with x_t^{(i)} \in \mathbb{R}^n being the system state, u_t^{(i)} \in \mathbb{R}^p the input, and w_t^{(i)} \sim \mathcal{N}(0, \sigma_w^2 I_n) the process noise.
The objective is to estimate the model parameters \Theta_t^{(i)} = \begin{bmatrix} A & B \end{bmatrix}, where [/katex]A[/katex] is the system evolution matrix and B is the input matrix. These parameters are estimated by solving the following optimization problem :
\hat{\Theta}_t^{(i)} = \arg \min_{\Theta_t^{(i)}} \|X_t^{(i)} - \Theta_t^{(i)} Z_t^{(i)}\|_F^2,
where X_t^{(i)} and Z_t^{(i)} are the stacked matrices of states and inputs over multiple trajectories and \|\ \|_F^2 is the Frobenius norm. Thus, for each client, its loss would be :
\mathcal{L}^{(i)}(\Theta_t^{(i)}) = \|X_t^{(i)} - \Theta_t^{(i)} Z_t^{(i)}\|_F^2.
In a federated setting, each client updates its local model, and a central server performs an aggregation without accessing the raw data.
2 Some Federated Algorithms
FedAvg (McMahan u. a., 2016)
Each of our M clients updates its model using by doing K gradient descent (SGD) on its local data :
\Theta_{t+1}^{(i)} \leftarrow \Theta_t^{(i)} - \eta \nabla \mathcal{L}^{(i)}(\Theta_t^{(i)})
where \eta is the learning rate and \nabla \mathcal{L}^{(i)}(\Theta_t^{(i)}) is the gradient of the local loss function. After our several K local iterations, the server aggregates the clients’ weights via a weighted average :
\Theta_{t+1}^{(global)} \leftarrow \sum_{i=1}^M w_i \Theta_t^{(i)}
where w_i is the weight of client i based on the size of its dataset. Then at each new iteration, \Theta_t^{(global)} is sent back to each client.
FedLin (Mitra u. a., 2021)
This algorithm improves FedAvg by incorporating a global gradient correction. Each client updates its model by subtracting the global gradient mean:
\Theta_{t+1}^{(i)} \leftarrow \Theta_t^{(i)} - \eta \left( \nabla \mathcal{L}^{(i)}(\Theta_t^{(i)}) + \nabla \mathcal{L}^{(i)}(\Theta_t^{(global)}) - g_t \right), \quad \text{ with}\ g_t = \frac{1}{M}\sum_{i=1}^M \nabla \mathcal{L}^{(i)}(\Theta_t^{(global)}).
This client update in FedLin helps manage heterogeneity by ensuring that local updates are more aligned with the global model, even when data distributions differ across clients by incorporating the average gradient g_t .
FedProx (Li u. a., 2020)
This variant introduces an additional regularization term to stabilize local updates and better address client heterogeneity. The clients’ loss function is modified as follows :
{\mathcal{L}^{(i)}}^{\text{prox}}(\Theta_t^{(i)}) = \mathcal{L}^{(i)}(\Theta_t^{(i)}) + \frac{\mu}{2} \|\Theta_t^{(i)} - \Theta_t^{(global)}\|_F^2,
where \mu is a hyperparameter controlling the proximity between the local and global models. Thus \nabla {F^{(i)}}^{\text{prox}}(\Theta_t^{(i)}) will be use instead of \nabla F^{(i)}(\Theta_t^{(i)}) in the step of client update (2).
3 Simulations and contribution
3.1 Simulation settings
For our simulation, we consider some matrices A_0 \in \mathcal{M}_{3 \times 3}(\mathbb{R}) , V \in \mathcal{M}_{3 \times 3}(\mathbb{R}) , B_0 \in \mathcal{M}_{3 \times 2}(\mathbb{R}) , and U \in \mathcal{M}_{3 \times 2}(\mathbb{R}) and variables (\gamma_1^{(i)}, \gamma_2^{(i)}) \sim U(0, \epsilon) to generate M matrices A^{(i)} and B^{(i)} such that :
A^{(i)} = A_0 + \gamma_1^{(i)} V, \quad B^{(i)} = B_0 + \gamma_2^{(i)} U.
Thus, each A^{(i)} and B^{(i)} is a perturbation of A_0 and B_0 , respectively, controlled by the parameter \epsilon , ensuring that the dissimilarity between the clients’ parameters remains always less than \epsilon , i.e.,
\max_{(i, j) \in \llbracket 1, M \rrbracket^2}\left\|A^{(i)}-A^{(j)}\right\| \leq \epsilon \ \text{and} \ \max_{(i, j) \in \llbracket 1, M \rrbracket^2}\left\|B^{(i)}-B^{(j)}\right\| \leq \epsilon.
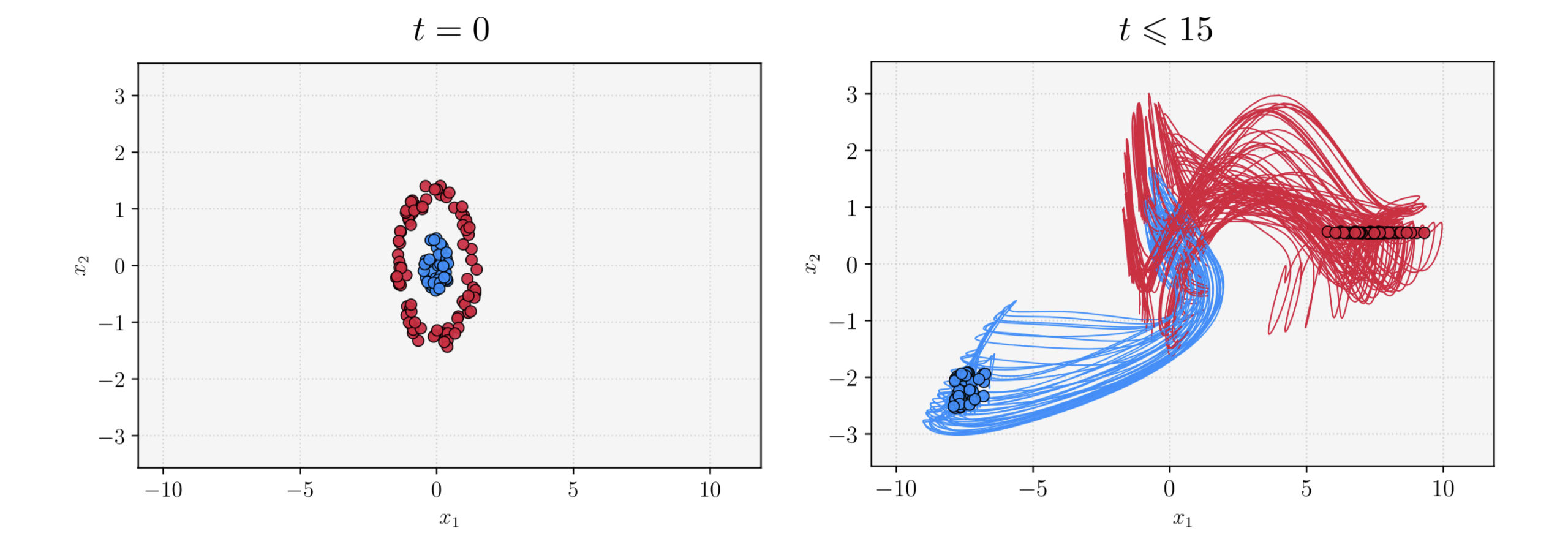
Bellow, an example of a trajectory for T=5 :
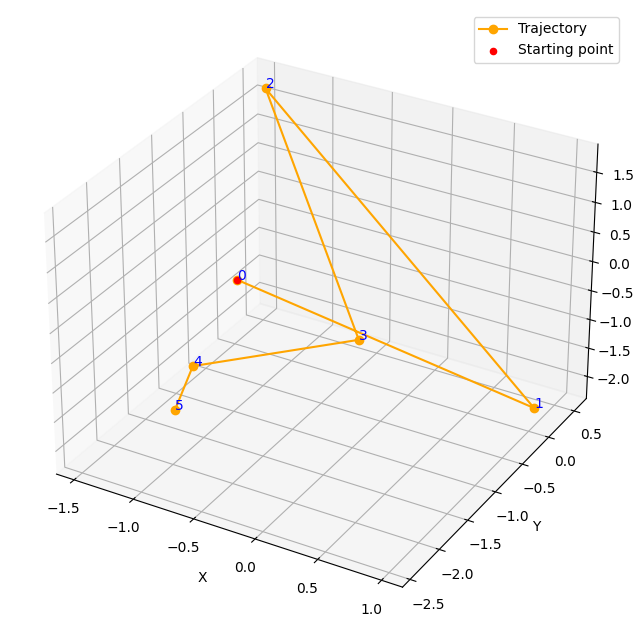
Figure 2. Example of a trajectory generated following (1)
Clarifications: ClientUpdate performs K=10 gradient descent iterations for all FL algorithms. The estimation error is defined as e_r = \frac{1}{q} \sum_{i=1}^{q} \|\bar{\Theta}_r^i - \Theta^{(1)}\| with q=25. All simulations run on an Intel Core i5-11400H CPU (6 Cores, 12 Threads, Max Turbo Frequency 4.50 GHz), with T=5 for all simulations.
3.2 Results
I reproduced the results from (Wang u. a., 2022) in Python and extended the analysis to include FedProx, providing a comprehensive comparison of federated learning algorithms, highlighting their ability to handle dissimilarities and optimize convergence rates.
Simulation 1: Variation in the Number of Clients
As shown in Figure 3, FedAvg and FedProx require more rounds than FedLin to converge, especially with fewer clients.
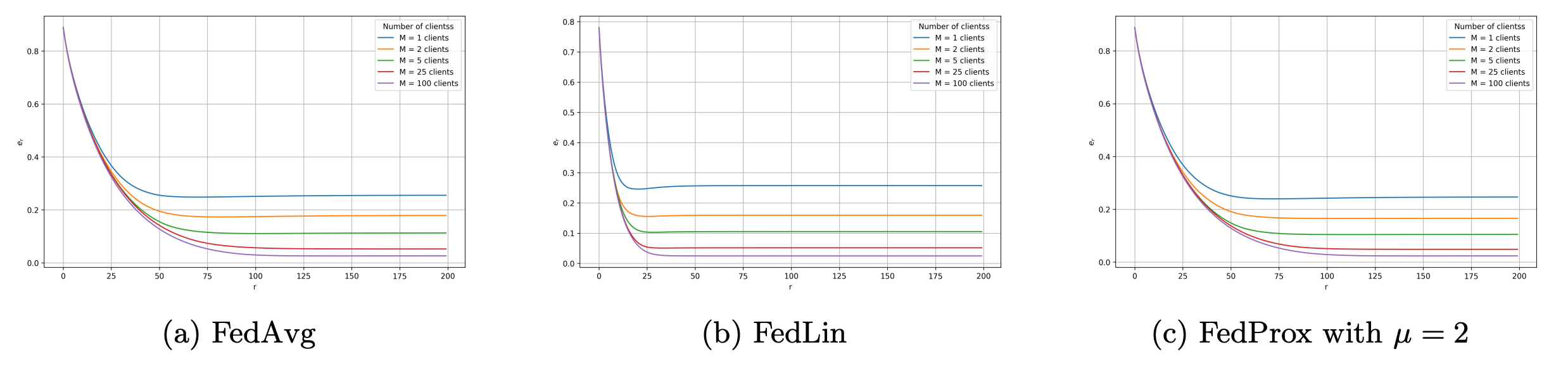
Figure 3. Estimation error per round for different number of clients M with N_i = 25 and \epsilon = 0.01.
Simulation 2: Variation in the Number of Rollouts
As shown in Figure 4, FedAvg and FedProx take more rounds to converge compared to FedLin, especially when the number of rollouts per client is low (N=5).
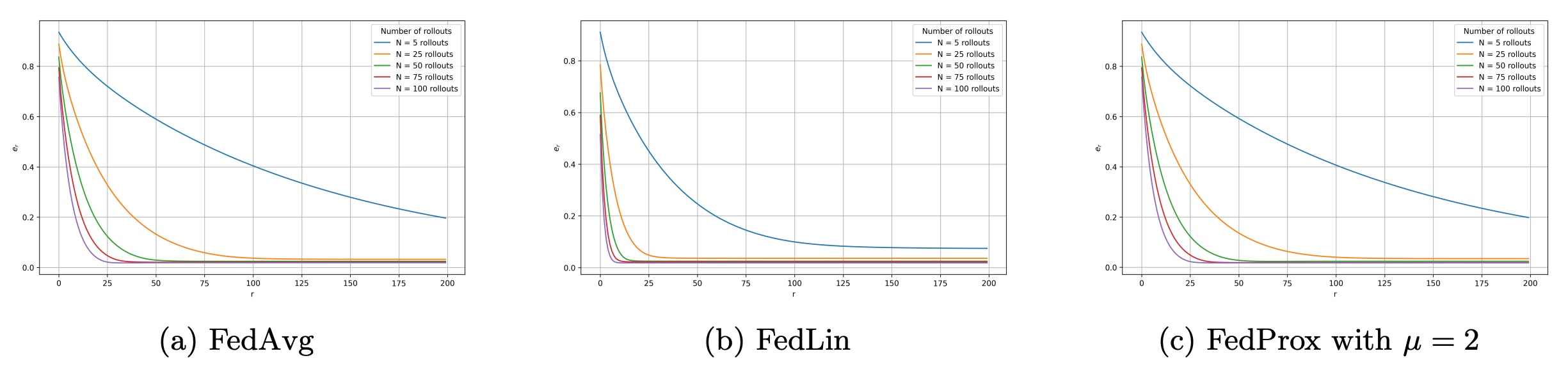
Figure 4. Estimation error per round for different number of rollouts N with M=50 and \epsilon = 0.01
Simulation 3: Variation in Dissimilarity ϵ Between Clients
As shown in Figure 5, as dissimilarity ϵ increases, FedAvg struggles, while FedLin continues to converge quickly. FedProx with \mu=2 performs well at moderate \epsilon values (smaller than 0.5), but does not regularize enough at \epsilon=0.75.
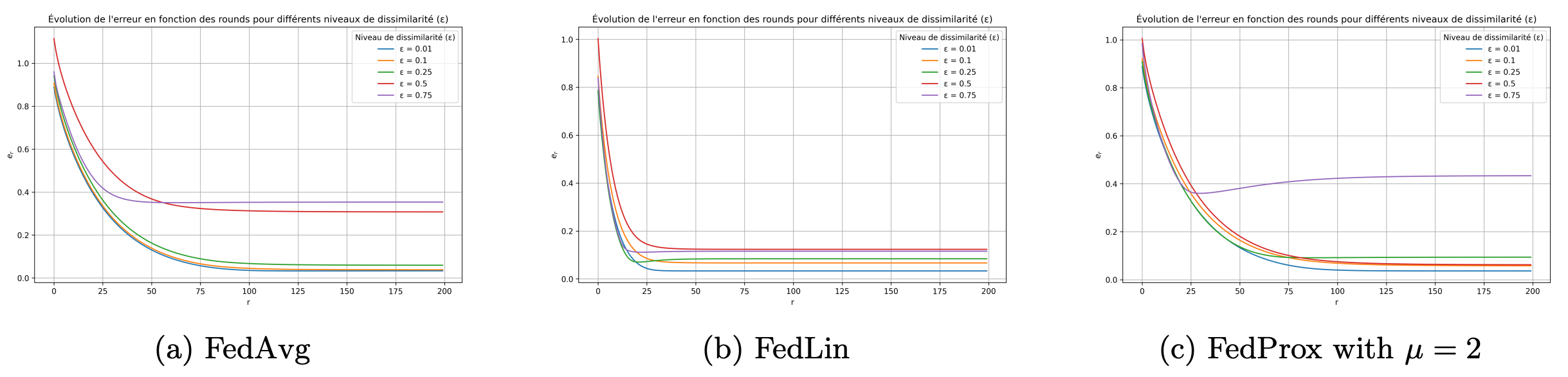
Figure 5. Estimation error per round for varying dissimilarity \epsilon with M=50 and N_i=25.
Simulation 4: Computation Time
As discussed in previous simulations, while FedLin converges in fewer iterations, FedProx, with appropriate \mu values, performs similarly in terms of error rates. However, FedProx executes each round faster than FedLin. As shown in Figure 6a, although FedProx takes 100 rounds compared to FedLin’s 25 in scenarios of simulation 3, it still completes the process more quickly. On average, FedProx is four times faster per round, as shown in Figure 6b.

Figure 6. Comparison of execution times for different FL solvers
4 Conclusion

Table 1: Comparison of FedAvg, FedLin, and FedProx algorithms.
(a) Cumulative execution time for different FL solvers with M=50, N=25, and \epsilon = 0.01.
(b) Average time of execution per round for different FL solvers.
References
[Li u. a. 2020] Li, Tian; Sahu, Anit K.; Zaheer, Manzil; Sanjabi, Maziar; Talwalkar, Ameet; Smith, Virginia (2020) Federated Optimization in Heterogeneous Networks, https://arxiv.org/abs/1812.06127[McMahan u. a. 2016] McMahan, H. B.; Moore, Eider; Ramage, Daniel; Hampson, Seth; Arcas, Blaise A. y (2016) Communication-Efficient Learning of Deep Networks from Decentralized Data, https://arxiv.org/abs/1602.05629
[Mitra u. a. 2021] Mitra, Aritra; Jaafar, Rayana; Pappas, George J.; Hassani, Hamed (2021) Linear Convergence in Federated Learning: Tackling Client Heterogeneity and Sparse Gradients, https://arxiv.org/abs/2102.07053
[Wang u. a. 2022] Wang, Han; Toso, Leonardo F.; Anderson, James (2022) FedSysID: A Federated Approach to Sample-Efficient System Identification, https://arxiv.org/abs/2211.14393
|| Go to the Math & Research main page





{kind=link}
{kind=link}